随着人工智能的飞速发展,多模态融合技术正成为推动认知智能和虚实世界融合的关键力量。在这里,您将全方位了解多模态融合机制、视觉-语言对齐、跨模态嵌入、虚实融合与最新评测平台,并通过丰富图文和可视化,轻松掌握2025前沿趋势!
多模态融合机制
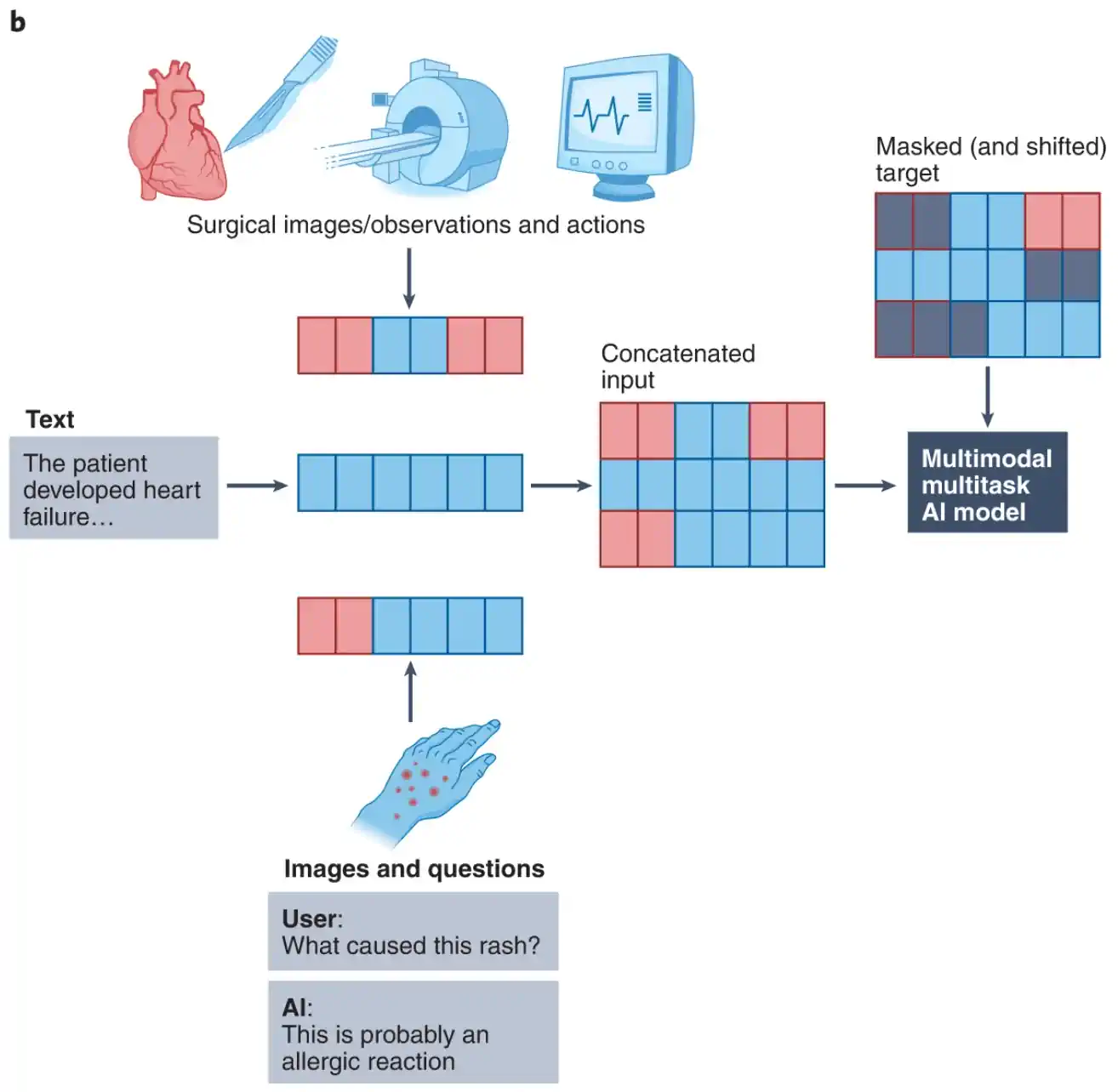
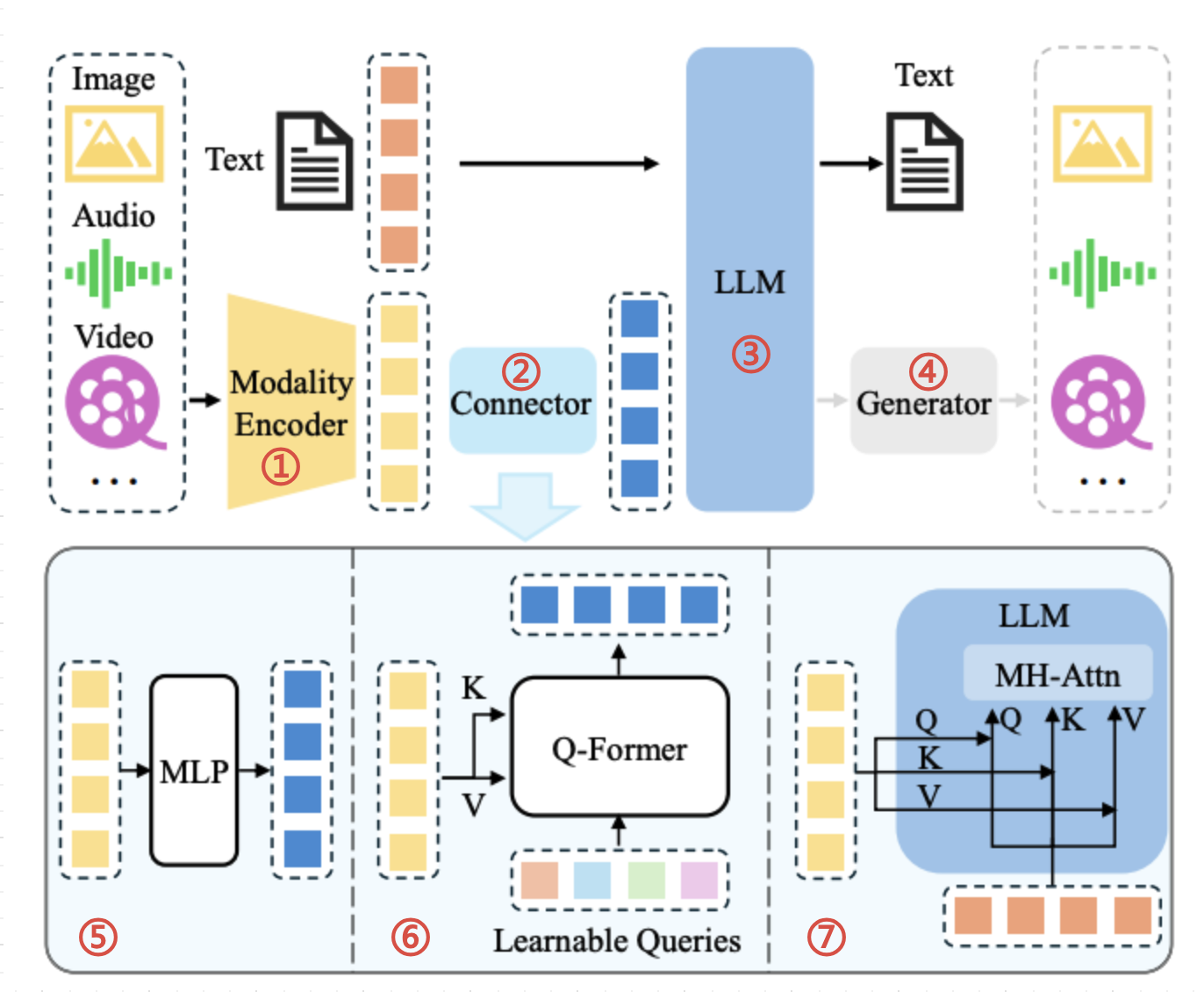
多模态融合是指整合图像、文本、语音、传感器等不同模态的信息,实现更为丰富和高效的智能感知与决策。2024年ICLR顶会讨论的前沿方法主要包括:
- 特征融合:拼接/加和不同模态的向量,如图像特征与文本描述。
- 对齐融合:通过自注意力、交叉注意力建立模态间语义匹配。
- 对比融合:如CLIP模型使用对比损失将图文映射到联合空间。
- 生成融合:如Diffusion等生成式AI通过跨模态预测或重构提高泛化。
应用领域包括智能医疗、机器人、智能城市、自动驾驶等。
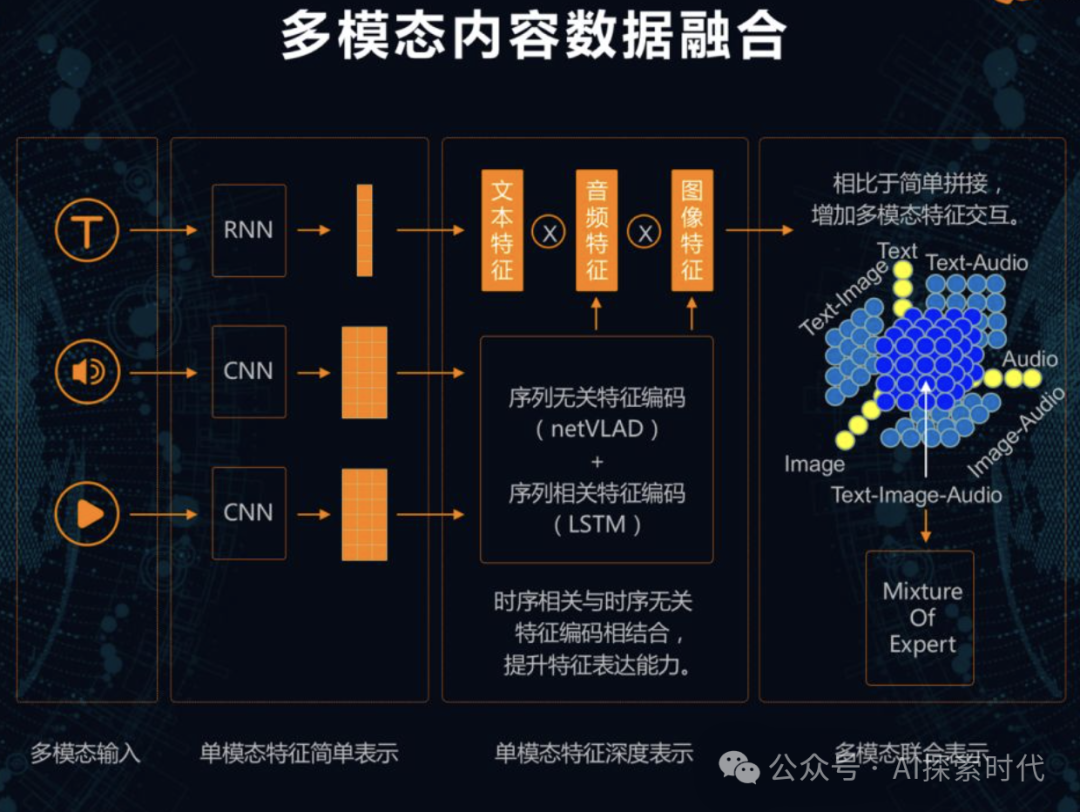
视觉-语言对齐技术

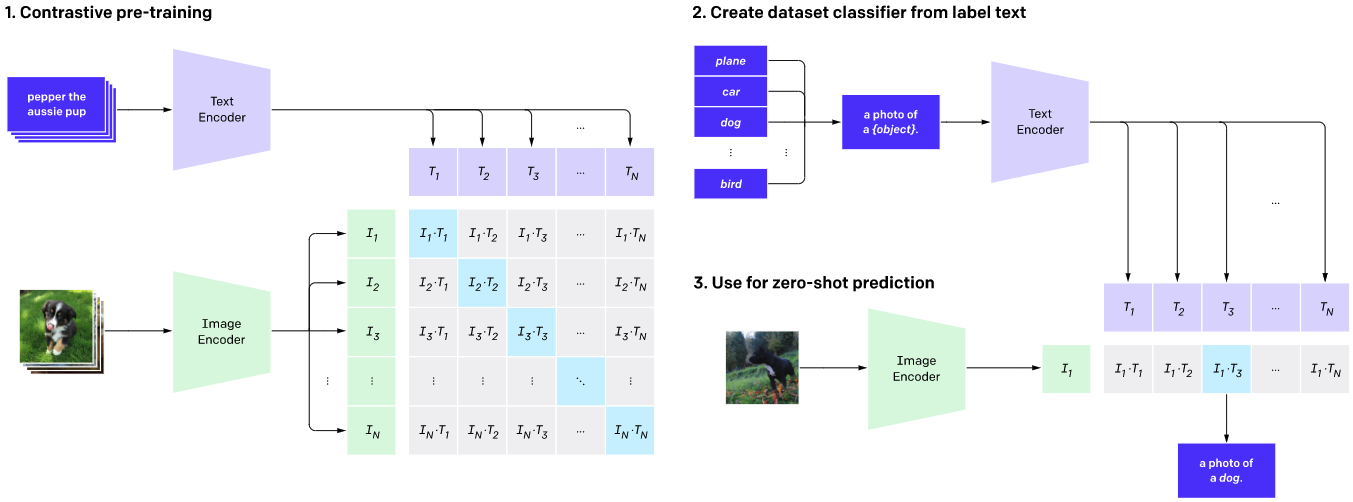
视觉-语言对齐(V-L Alignment)是现代多模态智能的核心。CLIP等模型将图片和文本编码后投影到同一隐空间,通过对比学习大幅提升了跨模态检索、图文生成等能力。
- 自注意力与交叉注意力机制提升了信息对齐的准确性。
- 基于Transformer架构将图像分块作为“单词”处理,实现类文本推理。
- 如X-VLM实现了多粒度空间对齐,图片语句关系理解更深入。
落地案例:图片自动标注、视觉问答系统、公益领域辅助推理等。
跨模态嵌入与机器学习
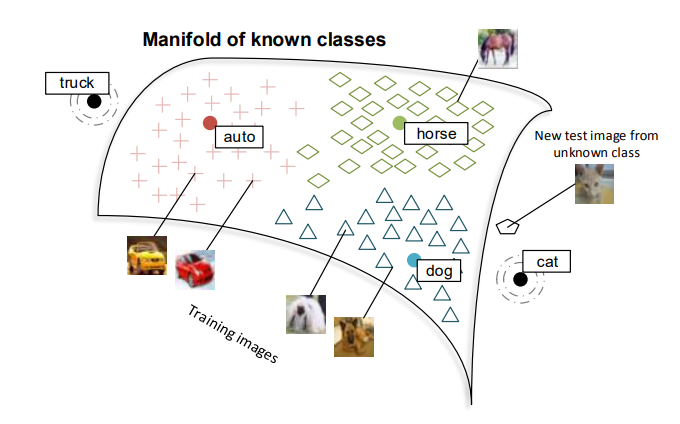
跨模态嵌入(Cross-modal Embedding)可将图像、文本、语音等多源数据映射到同一向量空间,实现相互检索、比较和联合推理。例如ImageBind将多达六种模态映射统一嵌入,有效提升AI的泛化能力。
- 联合嵌入学习提升了多模态AI的协同表现
- 嵌入空间流形结构有利于信息迁移与多模态检索
- 支撑自动化推荐、跨模态内容检索、多媒体内容生成等场景
图像理解链路与智能推理

现代图像理解链路包含视觉编码、特征抽取、多模态融合、知识推理以及自然语言生成等多阶段。如GLM-4V等多模态大模型,通过深度神经网络实现全链路优化,任务涵盖检测、分割、问答、推理等。
- 融合领域知识,提升AI在医学、工业、金融等场景下的解释力
- 支持零样本检索、开放式问答与复杂因果推断
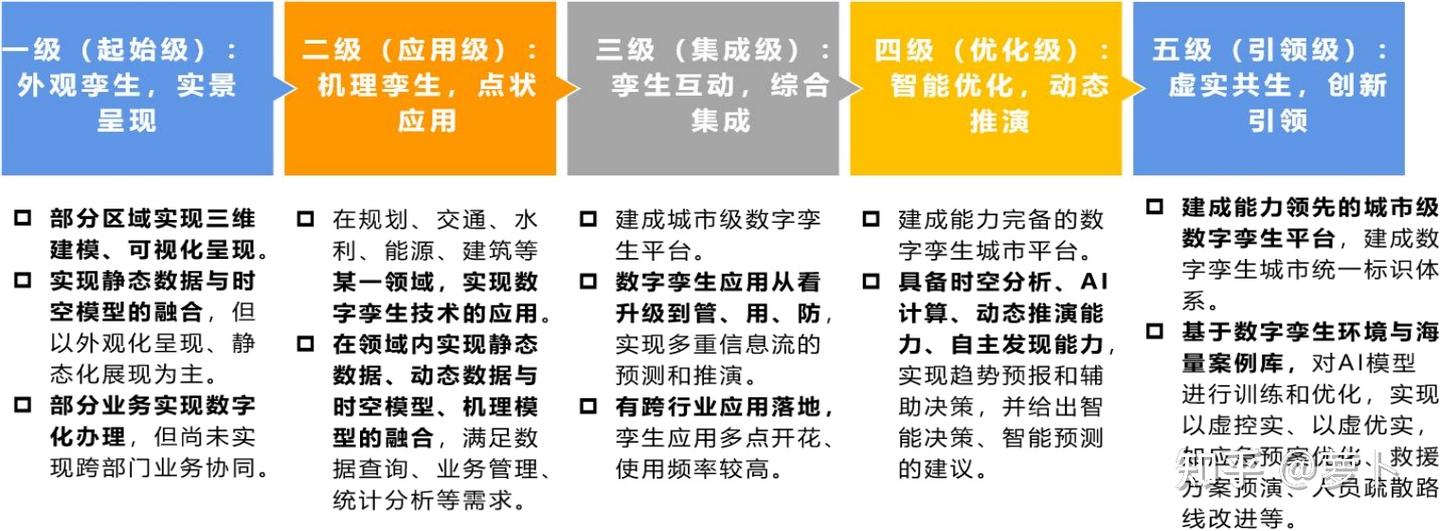
虚实融合(数字孪生 & 虚拟现实)
数字孪生技术用虚拟数字体完全映射现实物理体,实现虚实共生和交互。发展阶段包括:单向仿真、互动融合、共生一体等。
典型应用:数字孪生城市、智慧制造、应急调度等。
- 多模态数据流驱动场景实时还原
- 数实同步、分析预测和决策闭环
- 推动工业智能化、城市数字化转型


迷你多模态理解评测平台:MMBench
- 能力维度全面:感知、推理、跨模态检索、视觉问答等20+细分类别
- 评测更加客观:采用圆形评测与大模型自动评判,准确性提升20%
- 支持多语言:提供中英两套数据集,适用国际评测
- 数据开放:支持研究和企业自定义扩展
关联平台:MUGE、LVLM-eHub、MEGA-Bench等丰富多模态评测生态。

前沿趋势与展望
2025年多模态AI正以跨领域、泛模态的方向高速进化。从融合机制到智能推理,从虚实结合到全新评测,技术创新正驱动智能世界的无限可能。
未来,多模态大模型将深度赋能医疗、金融、工业、城市管理等场景,引领虚实共生的智慧社会新纪元。